Retrieval-Augmented Generation, known as RAG, harnesses the capabilities of LLMs (Large Language Models) to offer an effective method for accessing external information. LLMs comprehend the inquiry and leverage the contextual details in the given external materials to formulate a response on the subject. This process essentially bridges the gap between the vast general knowledge of an LLM and the specific, often niche, information contained within a user’s own documents. The aim is to create a system that doesn’t just regurgitate generic answers but provides tailored responses grounded in real, verifiable data.
This series of posts outlines an entire personal RAG project where I aim to detail my construction process, discuss the documents utilized, share the challenges faced, and highlight what improved its effectiveness. This project wasn’t just a theoretical exercise; it was a practical application of cutting-edge technology to solve a real-world problem. I wanted to create a system that could handle complex document analysis and provide accurate answers to detailed questions, much like a personal, highly efficient research assistant.
The project encompasses all elements of RAG, including document retrieval and preparation, as well as a chat-like interface that enables users to pose questions to the system and get responses. This involved not only the technical aspects of building the system but also the user experience, ensuring that the interface was intuitive and the responses were presented in a clear, understandable manner.
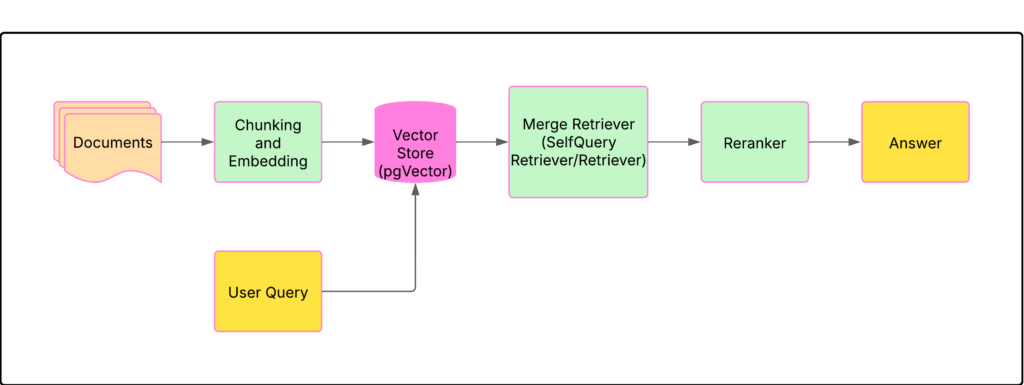
LLet’s go through every point in the diagram:
- Documents: The input data that we would like to analyze in this project are PDFs from the Spanish open data portal, which are documents related to subsidies for companies in Spain. Our system will enable users to pose questions about these subsidies and will return answers based on the content of the documents. These PDFs were often dense, filled with legal and financial jargon, and varied significantly in structure and content. This meant that the system needed to be robust enough to handle a wide range of document formats and complexities, extracting relevant information accurately and efficiently.
- Chunking and Embedding: The texts need to be processed to be system-compatible and inputted into our LLM models; the texts need to be divided into chunks and placed in a vector database that will hold both the chunks and their corresponding embeddings. We can choose various types and sizes of chunks with varying outcomes, which will be elaborated on in another post. The embedding process is crucial as it transforms the text into a numerical representation that captures its semantic meaning. This allows the system to understand the context of the query and find relevant documents, even if they don’t contain the exact keywords. Experimenting with different chunk sizes and embedding models was a key part of optimizing the system’s performance.
- Vector store: The most critical component of the RAG system, the Vector store (database) holds the documents and the embeddings. It is then able to fetch the pertinent documents with the information that the user needs according to similarity. Following some trial and error, pgVector emerged as my preference for this task given its performance and stability. The efficiency of the vector store directly impacts the speed and accuracy of the retrieval process. A well-optimized vector store can quickly identify the most relevant documents, ensuring that the LLM has access to the information it needs to generate accurate and contextually appropriate responses.
- Retrievers: The task of a retriever is to fetch the pertinent documents from the vector store for the user query; various retrievers are present. The combination of retrievers in the correct manner enhances the relevance of the retrieved documents significantly.
- Retriever: Default retriever. It is possible to modify the type of search (default is similarity) and the number of documents to be retrieved can be configured. This basic retriever provides a solid foundation for the system, allowing for simple similarity searches and configurable retrieval parameters.
- SelfQueryRetriever: This type of retriever has been really helpful in this project because of the characteristics of the documents used here. A list of metadata field and the meaning can be set and the retriever will look for those in the query. Really powerful. The ability to incorporate metadata into the retrieval process significantly improved the accuracy of the system, allowing it to filter documents based on specific criteria and provide more targeted responses.
- Retriever: Default retriever. It is possible to modify the type of search (default is similarity) and the number of documents to be retrieved can be configured. This basic retriever provides a solid foundation for the system, allowing for simple similarity searches and configurable retrieval parameters.
- Reranker: Assists in ranking the documents post-retrieval to enhance the accuracy of the retrieved documents by assigning a score based on the document’s relevance to the given query. This final step ensures that the most relevant documents are prioritized, improving the overall quality of the responses generated by the LLM.
In the upcoming posts of this series, we will explore each of these components along with the code utilized to construct the entire system. I’ll share the specific challenges I faced, the solutions I implemented, and the lessons I learned along the way.